EPiServer Find related content
In a website, it’s quite common to show related content on a page. In EPiServer, there are a number of options to accomplish this. In this blog, I would like to explain probably the easiest solution to implement, but on the other hand also, the most complex option when using all configurations options.
Using tags on pages gives web editors full control what related content needs to be shown. A useful NuGet package when working with tags is Geta.Tags, created by Geta. When this package is installed a tag property can be defined on a page type. This property gives web editors the ability to enter multiple tags in a text field. With the FindPagesWithCriteria method or with EPiServer Find it’s quite easy to build a query to retrieve related content based on the tag property.
Categories
Another option is categories, standard functionality of EPiServer. Categories can be defined in the Admin mode of EPiServer. Then categories can be selected on every page. The same as with tags, the FindPagesWithCriteria or EPiServer Find can be used to build a query to get related content based on categories.
More/Like - Find
As mentioned in some of my previous blogs, EPiServer Find is built on top of Elastic Search. The API of Find supports a lot of feature of Elastic Search. One of those features is more_like_this, which gives you the ability to find documents that are ‘like’ a piece of text. Let me first explain how this works.
First the input text (or how it’s called Elastic Seach the input document) is analyzed. Each term in Elastic Search gets a tf-idf (term frequency-inverse document frequency) value. This value indicates how important a term is in a document. So when the input text is being analyzed the terms with the highest tf-idf are used to build a query to find documents that have similar terms.
In EPiServer Find it’s quite simple to implement this feature, let me show a code sample:
_client.Search<ArticlePage>()
.MoreLike("Enjoy A Vacation In Phuket With Best Phuket Golf Courses")
.GetContentResult();The MoreLike method accepts a string parameter, that will be the text for getting related content. Just as with all queries that are built with the Find API, a Elastic Search query is generated and send to the server of EPiServer. Below a sample JSON request that is generated when using the MoreLike method.
{
"query": {
"filtered": {
"query": {
"filtered": {
"query": {
"more_like_this": {
"like_text": "Enjoy A Vacation In Phuket With Best Phuket Golf Courses"
}
},
"filter": {
"term": {
"___types": "EPiServer.Core.IContent"
}
}
}
},
"filter": {
"term": {
"___types": "Site.Models.Pages.ArticlePage"
}
}
}
},
"fields": [
"___types",
"ContentLink.ID$$number",
"ContentLink.ProviderName$$string",
"Language.Name$$string"
]
}As I mentioned in the introduction part of this blog, it can also be quite complex to implement the MoreLike method of EPiServer. There are a number of configuration options that can be set.
Minimum document frequency – integer
This setting indicates in how many other documents a term must occur otherwise, the term will be ignored.
Maximum document frequency – integer
Specify the maximum number a term may occur in other indexed documents otherwise, the term will be ignored.
Percent terms to match – integer
The percentage of terms that needs to match.
Minimum term frequency – integer
Specify how many times the terms must occur in the input document (text).
Minimum word length – integer
Set the minimum number of characters that a term must contain.
Maximum word length – integer
Set the maximum number of characters that a term may contain.
Maximum query terms – integer
Specify how many terms can be used to build the query.
Stop words – string
Words that should be ignored in the input document.
Time for some examples!
I have created a demo website that contains the MoreLike functionality. This website contains several article pages. To demo the more/like functionality of EPiServer I have created a page and a configuration section to easily modify the input parameters.

In the drop-down list all articles are loaded, so the idea is to select an article from the drop-down then set the configuration options and press the search button. The page name of the selected article is used to get related content. So now we can easily test some scenarios with the configuration options. As you can see in the result table a lot of items are shown. Let’s play around a little bit with the configuration settings.
What I mentioned earlier, stop words are used when you would like to ignore words from the input document. For instance, if I add all words (online, dominance, of, video, adds) except for ‘marketing’ then only that word is used to get other related pages.
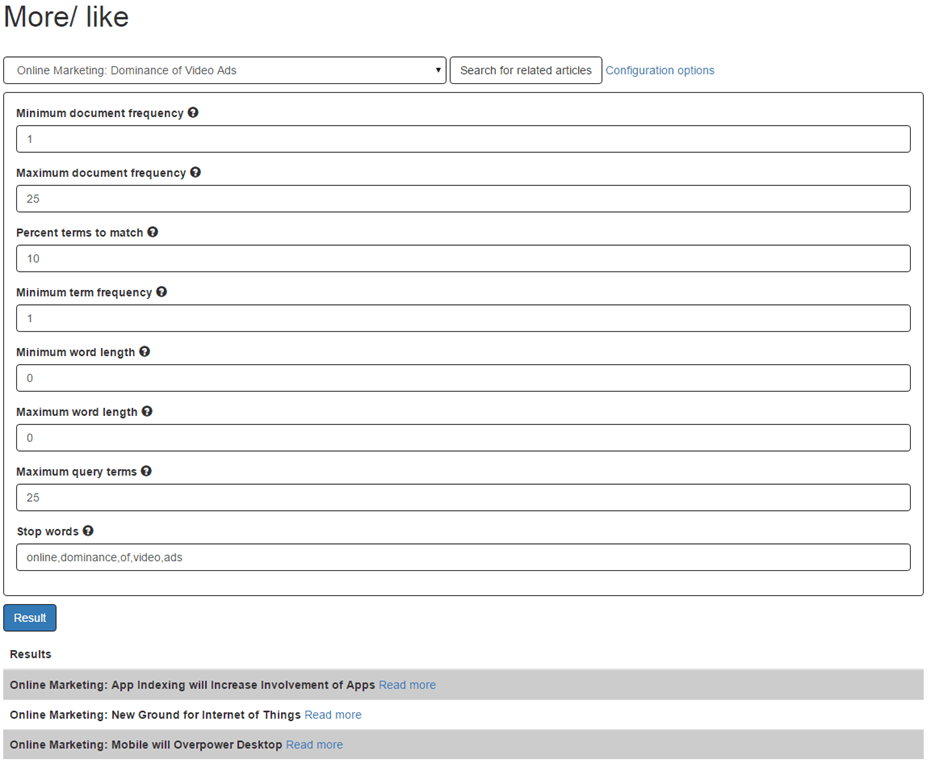
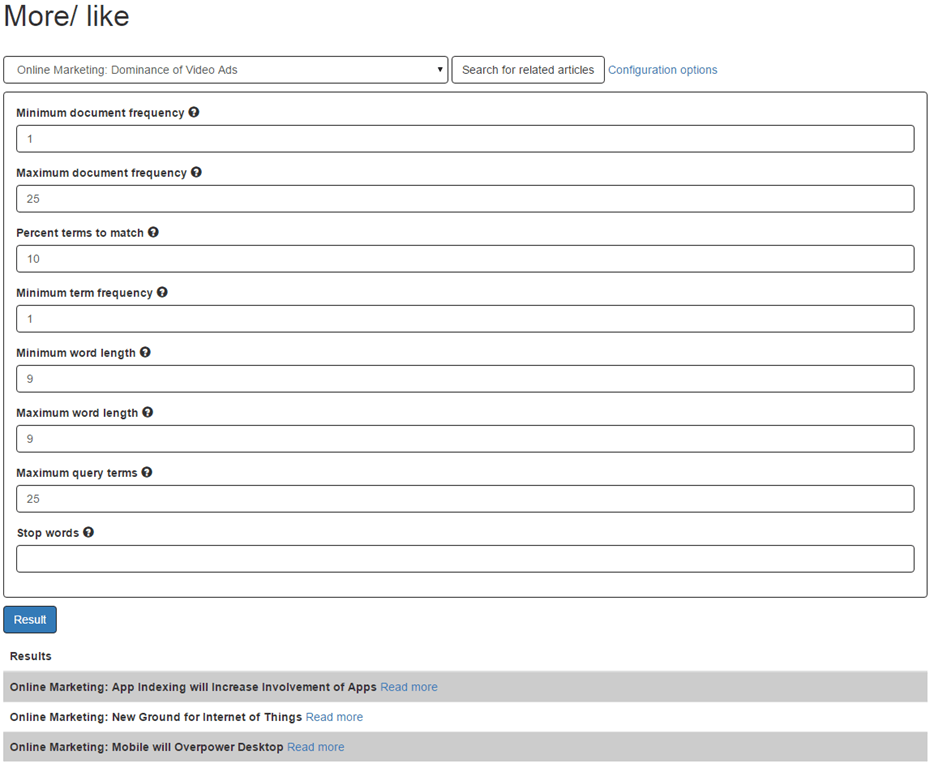
Now you can see that only three pages are returned that contains the word ‘marketing’ (what actually is true as you can see in the title of the pages). We could also accomplish the same result not by using the ‘stop words’ setting but with the ‘minimum word length’ and the ‘maximum word length’ setting. The word marketing contains nine characters. So what I can do is set the ‘minumum word length’ and the ‘maximum word length’ to nine. This means that only words that contain nine characters are used in the query by Elastic Search.
The ‘minimum term frequency’ setting reflects on the input document. In this case, the input document is the name of the page ‘Online Marketing: Dominance of Video Ads’. With this setting, terms (words) can be ignored if a term occurs in the input document under a specified number. For example, I can set the ‘minimum term frequency’ to 2 which means (if I use the same configuration options as the previous example what means that only the word ‘marketing’ is used) that the word ‘marketing’ is ignored because it only occurs once in the input document.
The ‘minimum document frequency’ can be used to set how often a term must occur in other indexed documents otherwise the term will not be used. If I use the same configuration (only use the word ‘marketing’) and I set the ‘minimum document frequency’ to 5 no items will be returned because only 4 pages contain the word ‘marketing’. If I set the value to 2 then items will be returned by Find.
The API of EPiServer Find contains some extension methods to set the different configuration settings.
_client.Search<ArticlePage>()
.MoreLike(article.PageName)
.MinimumDocumentFrequency(minimumDocumentFrequency)
.MaximumDocumentFrequency(maximumDocumentFrequency)
.PercentTermsToMatch(percentTermsToMatch)
.MinimumTermFrequency(minimumTermFrequency)
.MinimumWordLength(minimumWordLength)
.MaximumWordLength(maximumWordLength)
.MaximumQueryTerms(maximumQueryTerms)
.StopWords((!string.IsNullOrEmpty(stopWords) ? stopWords.Split(',') : Enumerable.Empty<string>()))
.Filter(x => !x.ContentLink.ID.Match(articleId))
.Select(a => new
{
Title = a.PageName,
Url = _urlResolver.GetUrl(a.ContentLink)
})
.Take(100)
.GetResult();If you would like to play around with the configuration options you can get the source code of my GitHub account.
I think the more/like feature of EPiServer is handy, but it can be quite challenging to set the right configuration settings. If the web editor should have full control about what related content is I would suggest using tagging or categories.
 Twitter
Twitter LinkedIn
LinkedIn GitHub
GitHub